
A First Step Toward AI Search (and What Comes After)
I’ve been thinking a lot about what “search” really means in the age of AI. Oh yes! after seeing the high of setting up my first vector database.

Not keyword search. Not filters. But the kind of search where you ask a system a question and expect it to understand what you’re really after, and just as importantly, what context it might be missing.
This feels like the first real step toward how AI systems will reason going forward.
Vector Search: When Meaning Is Close
Vector search is where most GenAI journeys start, and for good reason.
It works by turning text into numbers and placing similar meanings close together in a mathematical space. When you search, the system retrieves things that feel similar in intent or language.
This is great for semantic matching.
Ask for “electric toothbrush” and you’ll get… electric toothbrushes.
But there’s a quiet limitation here.
Vector search struggles when two things are related but not similar.
A login event and a financial transaction don’t live near each other in vector space, even if both are part of the same fraud story.
Similarity isn’t the same as relevance.
Knowledge Graphs: When Meaning Is Connected
This is where graphs enter the picture.
A knowledge graph doesn’t care if two things sound alike. It cares about how they’re connected. Entities are nodes. Relationships are edges. Meaning emerges from how many “hops” it takes to get from one thing to another.
Graphs shine when:
relationships matter more than wording
context lives across systems
the question is “how is this connected?” rather than “what is this similar to?”
Think social networks, supply chains, audits, investigations, anywhere cause, sequence, or dependency matters.
Scoring Isn’t a Single Step Anymore
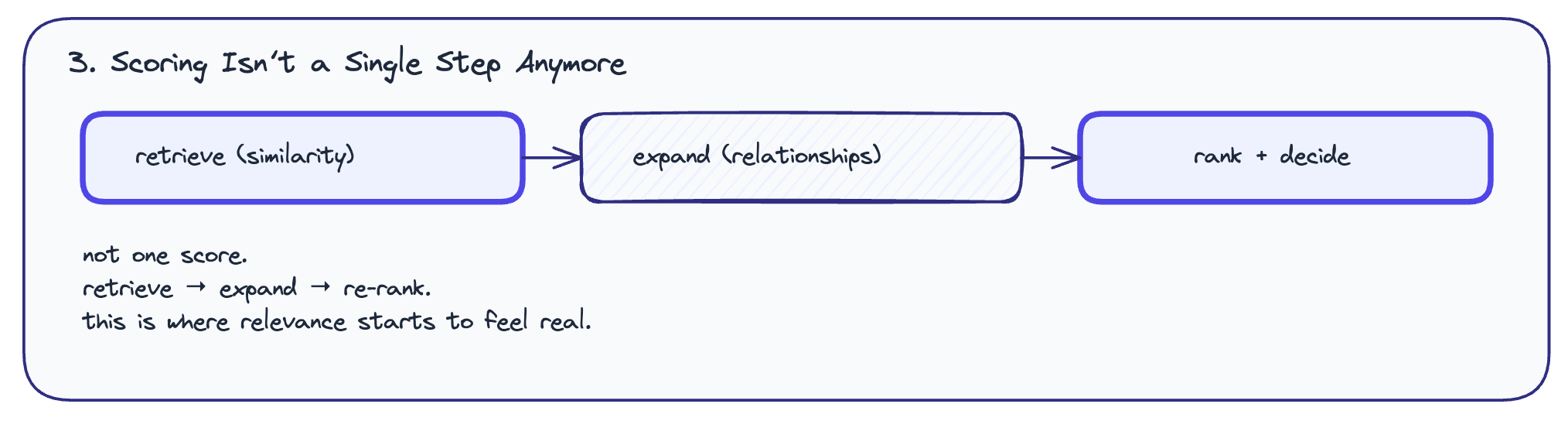
The most important insight for me wasn’t vector vs graph.
It was how scoring actually happens in real AI systems.
Modern search is almost always hybrid.
Pattern 1: Vector first, graph later
You start with similarity. Grab the top results. Then expand through relationships.
This is how you recommend a lubrication gel after someone adds fissure meds to their cart.
Not because they’re similar, but because they belong to the same world.
Pattern 2: Graph first, vector later
You start wide. Pull a large set of related entities. Then rank them by similarity.
This is how “friends of friends” becomes “friends of friends you’ll actually get along with.”
In both cases, scoring isn’t just distance in vector space.
It’s distance plus structure.
Why GraphRAG Matters

The most convincing example was GraphRAG.
A system asked:
“What are the sales prospects for Company X in India?”
Vector-only retrieval found positive articles. The model answered optimistically and confidently wrong.
GraphRAG did something subtle:
It found the company via vectors
Then followed relationships the text never made explicit
A logistics partner
A canal
A blockage
Suddenly, the answer changed. Not because of new text, but because of missing context now made visible.
This is the difference between sounding smart and being correct.
Where This Leaves Me
I’m starting to see AI search less as “better retrieval” and more as progressive understanding.
Vectors help you enter the problem space
Graphs help you navigate it
The model synthesises only after both have done their job
This feels like the natural evolution of search:
from matching words
to matching meaning
to understanding systems.
This is just the beginning. The real work lies ahead in how we design these layers, how we control scoring, and how we prevent confidence without grounding.

That’s a journey that interests me next.
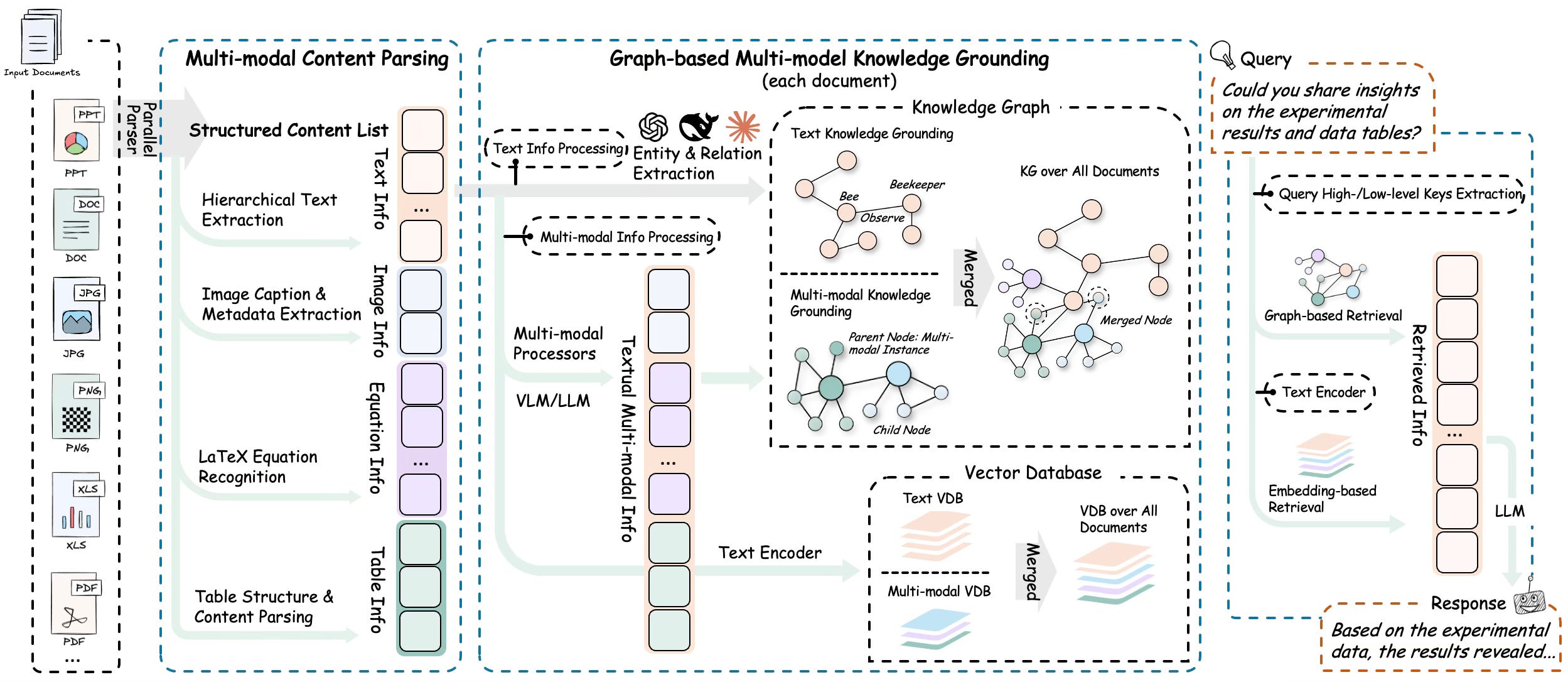
A small note on where I’m learning this from
A lot of my current thinking around AI search especially the
“retrieve → expand context → re-rank → answer”
shape is being influenced by the RAG-Anything work from HKUDS. Their framework diagram helped me see the pipeline as a system, not a single retrieval trick.
Framework diagram
Repository: https://github.com/HKUDS/RAG-Anything.git
Thanks:
Thank you to the HKUDS team and contributors, open diagrams and open repos like this make it easier for builders like me to learn in public, iterate fast, and stay honest about what we’re actually standing on.
It's interesting how the article highlights that similarity isn't relevance, and what if an AI search systm, relying too heavily on vector space similarity, inadvertently obscured complex, nuanced truths and human relationships in scenarios like social justice audits, simply because the relevant concepts don't 'feel' close?